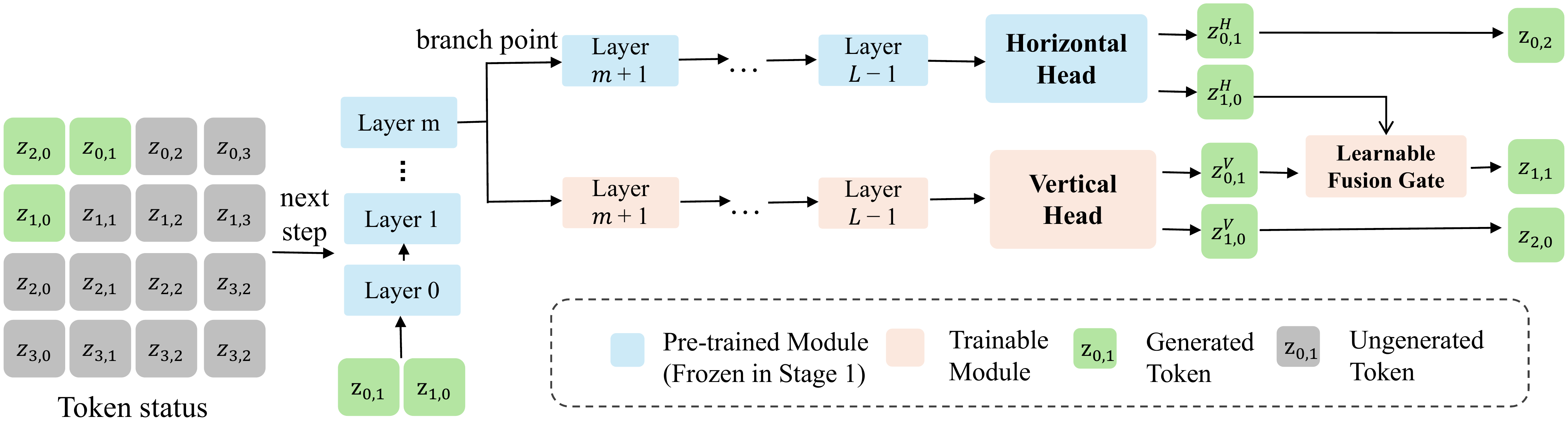
Three key designs make FlashAR both fast and easy to adapt:
- Intermediate Branching. The vertical head is attached at an upper-intermediate layer rather than the final layer, where features are still semantically rich and not yet specialized to horizontal prediction. Both branches run concurrently with no extra critical-path depth.
- Learnable Fusion Gate. A lightweight MLP-based gate adaptively balances horizontal and vertical logits at each spatial position, avoiding the blurring artifacts of naive averaging.
- Two-Stage Adaptation. Stage 1 freezes the backbone to initialize the vertical head; Stage 2 jointly fine-tunes everything. This keeps post-training stable and data-efficient.
At inference time, FlexAttention compiles sparse diagonal masks on-the-fly and KV caches are updated in batched operations, translating the theoretical parallelism into real wall-clock gains.